AFL++: Fuzzer de nueva generación

Introducción y evolución desde AFL
American Fuzzy Lop Plus Plus (AFL++) es un fork avanzado del afamado fuzzer AFL (American Fuzzy Lop) original, diseñado para llevar el fuzzing guiado por cobertura al siguiente nivel. AFL, creado por Michał Zalewski en 2013, revolucionó las pruebas automatizadas al emplear algoritmos genéticos y retroalimentación de cobertura para generar casos de prueba que exploran profundamente las rutas de ejecución de un programa. Sin embargo, el desarrollo de AFL se estancó tras su última actualización en 2017, dejando numerosas mejoras propuestas por la comunidad y la academia fuera de la versión principal. AFL++ surge en 2019 como sucesor comunitario para integrar esas mejoras acumuladas, optimizar el rendimiento y agregar nuevas funcionalidades manteniendo la solidez del motor original de AFL.
AFL++ conserva la esencia del AFL original – un fuzzer evolutivo impulsado por cobertura – pero incorpora parches y técnicas de fuzzing de última generación desarrolladas en años recientes. Por ejemplo, AFL++ integró power schedules de AFLfast (que priorizan explorar rutas menos frecuentes), el mutador avanzado MOpt (optimización de mutaciones probabilística), y mejoras para fuzzing binario en modo emulación con QEMU. Asimismo, añade compatibilidad con modos persistentes, herramientas auxiliares y parches como CmpLog (inspirado en RedQueen) para resolver comparaciones mágicas. En resumen, AFL++ es una evolución natural de AFL que combina aportes de la academia y la comunidad para ofrecer un framework de fuzzing más potente y extensible. Ha sido utilizado exitosamente para descubrir numerosas vulnerabilidades en proyectos reales (por ejemplo, múltiples CVEs en VLC), consolidándose como una herramienta imprescindible en el arsenal de un experto en ciberseguridad.
Arquitectura interna de AFL++
Desde el punto de vista interno, AFL++ comparte la arquitectura general de AFL, basada en un enfoque grey-box fuzzing (caja gris guiada por cobertura). A grandes rasgos, AFL++ ejecuta iterativamente el programa objetivo con insumos semi-aleatorios, midiendo qué rutas de código se alcanzan y usando esta información para generar nuevos insumos cada vez más interesantes. A continuación se describen los componentes clave de su arquitectura y funcionamiento:
- Instrumentación y mapa de cobertura: Para saber qué partes del programa ejecuta un caso de prueba, AFL++ inserta instrumentación en el binario del objetivo. Típicamente, se compila el programa con un compilador especial (como
afl-clang-fast) que agrega instrucciones en cada bifurcación o bloque básico para registrar un hit en un mapa de cobertura en memoria compartida. Este bitmap (generalmente de 64 KB) actúa como registro global de las ramas ejecutadas. AFL++ soporta múltiples esquemas de instrumentación: el más común es LLVM PCGUARD (víaafl-clang-fast), que marca cada salto único, y también un modo LTO (Link-Time Optimization) aún más potente que permite instrumentar comparaciones y constantes de forma avanzada. En cualquier caso, el objetivo es obtener una traza compacta de ejecución para cada entrada, a fin de detectar nuevas rutas. - Forkserver y ejecución eficiente: Un desafío del fuzzing es lanzar el programa objetivo millones de veces. AFL/AFL++ solucionan esto con el mecanismo de forkserver: cuando iniciamos
afl-fuzz, éste arranca el binario objetivo en un proceso hijo y lo detiene justo antes demain(). Ese hijo actúa como un servidor que espera órdenes por tuberías (pipes) para bifurcar (fork) procesos nietos que ejecutarán realmente el caso de prueba. Cada vez que AFL++ quiere probar una nueva entrada, envía una señal al forkserver, el cual hace fork() de sí mismo (con el estado inicial ya cargado) y en el proceso resultante continúa la ejecución del programa con la entrada proporcionada. Este diseño evita el coste de cargar y relanzar el binario desde cero en cada iteración, reduciendo drásticamente la sobrecarga: la creación de procesos vía fork es mucho más rápida que iniciar un ejecutable completo. Al finalizar la ejecución (ya sea por terminación normal, crash o timeout), el proceso nieto muere y el forkserver queda listo para spawnear el siguiente. De esta manera, AFL++ logra tasas de ejecución muy altas (varios miles de casos por segundo en aplicaciones ligeras aprovechando el paralelismo a nivel de procesos y la inicialización única del binario. - Algoritmo genético y mutación de insumos: AFL++ mantiene una cola de casos de prueba (queue) que almacena entradas interesantes, es decir, aquellas que han revelado nuevas coberturas o comportamientos. Parte del núcleo de AFL++ es un algoritmo evolutivo que toma estas entradas y las muta de diversas formas para generar nuevos insumos, buscando gatillar comportamientos anómalos. Las mutaciones se aplican en etapas determinísticas (p.ej., volteo sistemático de bits, bytes y enteros, adición o sustracción de constantes, etc.) seguidas de etapas aleatorias más agresivas (havoc, splicing entre dos casos, etc.). Durante las fases deterministas iniciales, AFL++ prueba cambios graduados (bit a bit) para explorar pequeñas variaciones, mientras que en la fase caótica realiza alteraciones al azar, mezcla partes de diferentes entradas, inserta valores extremos conocidos (
0, 0xFFFF, INT_MAX, etc.), entre otras estrategias. Cada nuevo insumo ejecutado se evalúa: si produce nuevas ramas cubiertas (detectadas vía el mapa de cobertura) o algún efecto novedoso, se añade al queue como favourite para futuras mutaciones. AFL++ introduce además mutadores adicionales, como la capacidad de cargar diccionarios de tokens específicos del formato (e.g., JSON, XML) para insertar cadenas semánticamente relevantes, o el uso del mutador externo Radamsa para generar variaciones aleatorias avanzadas. El resultado es un mecanismo de fuzzing feedback-driven inteligente, que aprende de cada ejecución cuál es la mejor manera de expandir la exploración del código. - Manejo de fallos y timeouts: AFL++ detecta automáticamente si una ejecución termina en fallo (crash) o si se queda colgada (hang). Internamente, monitorea la señal con la que termina el proceso hijo: señales como SIGSEGV, SIGABRT, SIGILL, etc. marcan un crash que se registra (almacenando la entrada causante en
crashes/), mientras que si el tiempo de ejecución excede un umbral (timeout), se termina el proceso y se registra el caso enhangs/. Por defecto, AFL++ aplica un tiempo límite adaptativo según el comportamiento del programa, pero el usuario puede ajustar manualmente el timeout (-t) para castigar retardos. Igualmente, es posible restringir la memoria máxima usada por el proceso con-m(por defecto ilimitada), lo que previene que insumos patológicos agoten la RAM e incluso ayuda a descubrir bugs donde el programa no maneja bien fallos demalloc(). Cuando ocurre un crash, AFL++ registra el output de la corrida y el tipo de señal, facilitando el posterior análisis y deduplicación de fallos únicos. Es importante mencionar que AFL++ puede detectar ciertos errores de memoria no fatales usando técnicas especiales (ver sección de herramientas de análisis), pero típicamente se apoya en que las vulnerabilidades severas acaben provocando una terminación anómala del programa. - Modos persistente y deferred: Para objetivos particulares (como librerías o funciones que pueden invocarse repetidamente en un mismo proceso), AFL++ soporta un modo persistente que evita incluso el fork entre ejecuciones. En este modo, el código del objetivo se modifica (usando macros de AFL++ o APIs especializadas) para entrar en un bucle interno que procesa nuevas entradas sin salir del programa. AFL++ instrumenta ese bucle de manera que, tras varias iteraciones, igualmente realiza un fork fresco para evitar acumulación de estado. El modo persistente puede incrementar órdenes de magnitud la velocidad de casos por segundo al eliminar prácticamente todo el overhead de creación de procesos. AFL++ ofrece macros (
__AFL_LOOP()en el código C, por ejemplo) para facilitar esta técnica. De forma similar, el forkserver puede retrasarse (deferred) hasta que el programa esté en un estado listo para fuzzear – útil si el programa tarda en inicializar recursos; con deferred forkserver se inicia la instrumentación justo antes de la parte que nos interesa fuzzear, reduciendo tiempo ocioso. Estas capacidades son especialmente valiosas al fuzzear APIs dentro de procesos (p.ej., llamar a una función decodificadora miles de veces sin reiniciar el proceso). Honggfuzz, como veremos, también explota un enfoque similar de persistencia en procesos para lograr alto rendimiento.
En conjunto, la arquitectura de AFL++ combina instrumentación eficiente, ejecución rápida mediante fork/persistencia, y una estrategia de mutación guiada por cobertura. Además, incorpora numerosas características destacadas que amplían sus capacidades, las cuales resumimos a continuación.
Características destacadas de AFL++
AFL++ integra casi todas las optimizaciones y extensiones desarrolladas alrededor de AFL. Algunas de las más notables son:
- Soporte multiplataforma y variedad de instrumentación: AFL++ puede operarse en Linux, BSD, macOS y también fuzzear binarios de Windows PE a través de QEMU+Wine. Ofrece diversos modos de instrumentación:
- Compile-time: mediante wrappers de compilador (
afl-gcc,afl-clang-fast) o un plugin para GCC, que insertan el código de seguimiento de cobertura durante la compilación del programa objetivo. - Link-time (LTO): una modalidad que instrumenta a nivel de bitcode LLVM (usando
afl-clang-lto), permitiendo aplicar transformaciones globales como la instrumentación de comparaciones (CmpLog) de forma más profunda que el PCGUARD estándar. - Instrumentación binaria dinámica: con QEMU mode (
-Q) para instrumentar binarios sin código fuente mediante emulación rápida de CPU, Unicorn mode para fuzzear fragmentos de código o firmware en emulaciones de CPU a bajo nivel, y Frida/QBDI mode para instrumentar binaries (especialmente en Android) utilizando frameworks de dynamic binary instrumentation. Esta amplitud de opciones permite fuzzear tanto aplicaciones con código fuente (aprovechando instrumentación más rápida) como aplicaciones black-box.
- Compile-time: mediante wrappers de compilador (
- Mutadores avanzados y estrategias de generación: Incorpora mutadores de última generación:
- Power schedules (AFLfast): ajusta dinámicamente cuántas mutaciones realizar de cada entrada según su rareza de cobertura, para dar más energía a casos que cubren rutas poco frecuentes.
- MOpt: un sistema de mutación probabilístico que ajusta las operaciones de mutación en tiempo real según su efectividad, mejorando la eficiencia de explorar inputs válidos.
- NeverZero: parche que evita que los contadores de cobertura se reseteen a cero por overflow, lo que mejora ligeramente la detección de nuevas ramas.
- Radamsa y mutadores personalizados: opción de integrar el generador aleatorio Radamsa (
-R) como mutación adicional o exclusiva, y API para que el usuario implemente sus propios mutadores en C o Python e incorporarlos durante la ejecución. - Nuevas coberturas (CmpLog, Ngram): además de cobertura edge básica, AFL++ puede usar cobertura de comparaciones (CmpLog/RedQueen) que trata de inferir valores correctos para igualdades en el código instrumentado (e.g., si hay
if(x==0x1234)el fuzzer intenta deducir input que de 0x1234). También soporta cobertura de N-gramas de ramas, capturando la secuencia de N saltos consecutivos para proveer contexto y descubrir rutas dependientes de historial. Estas mejoras permiten profundizar en códigos con checksums, magia bytes o dependencias de contexto, problemas conocidos para fuzzers básicos.
- Soporte para fuzzing dirigido y selecciones de código: Aunque AFL++ en sí está orientado a exploración amplia, incluye funcionalidades para enfocar o restringir la búsqueda. Por ejemplo, soporta whitelists de funciones o áreas a instrumentar, de modo que uno puede instrumentar solo el código relevante (reduciendo ruido de cobertura). Herramientas derivadas como AFLGo implementan directed fuzzing asignando pesos según la distancia a un punto objetivo en el programa – AFL++ puede interoperar con este tipo de técnicas y ha sido usado como base para evaluar fuzzing dirigido en investigaciones recientes. En la práctica, esto significa que es posible orientar AFL++ para llegar a una función o ubicación específica (por ejemplo, una nueva función parcheada) con ajustes adicionales, aunque no sea su modo de operación por defecto.
- Librerías auxiliares para detección de errores: AFL++ incluye helper libs como libdislocator, libtokencap y libcompcov. Libdislocator es un sustituto de la libc malloc que fuerza fallos inmediatos en casos de corrupción de heap (sobreflows o usos después de
free), colocando las asignaciones junto a páginas no accesibles para provocar un segfault en escrituras fuera de rango. Al cargar esta librería (víaLD_PRELOADo la variableAFL_PRELOAD), se incrementan las probabilidades de que un heap overflow se manifieste como crash detectable. Libtokencap, por su parte, puede extraer cadenas recurrentes del input durante la ejecución para sugerir diccionarios de fuzzing automáticamente, mientras que libcompcov instrumenta comparaciones complicadas (ej. funciones hash) partiéndolas en operaciones más simples (LAF-Intel). Estas librerías ayudan a AFL++ a encontrar bugs sutiles que de otra forma podrían pasar inadvertidos.
En suma, AFL++ se destaca por combinar múltiples modos de instrumentación, mejoras de rendimiento, mutaciones inteligentes y utilidades avanzadas, todo configurable por el usuario experto. A continuación, exploraremos cómo utilizar AFL++ en la práctica, desde la instrumentación de binarios hasta el fuzzing dirigido, seguido del uso de herramientas complementarias para maximizar la eficacia del proceso.
Instrumentación de binarios: preparación del objetivo
Para aprovechar AFL++, lo primero es instrumentar o preparar el programa objetivo según el caso. Existen dos escenarios: que tengamos acceso al código fuente (fuzzing de caja blanca) o que solo dispongamos del binario compilado (caja negra). AFL++ soporta ambos casos con diferentes métodos:
- Instrumentación en compilación (código fuente disponible): Si contamos con el código, la manera recomendada es recompilar el programa con los compiladores de AFL++. Por ejemplo, podemos exportar
CC=afl-clang-fastyCXX=afl-clang-fast++antes de ejecutarconfigure && make, o invocar directamenteafl-clang-fastal compilar fuentes C (y C++). Esto inserta automáticamente la instrumentación de cobertura. Alternativamente, AFL++ proveeafl-gcc/afl-g++(wrappers sobre GCC) y un plugin para GCC>=10 que cumple la misma función. Un ejemplo mínimo de compilación sería:
# Compilar un objetivo con AFL++ (instrumentación LLVM)
$ AFL_HARDEN=1 afl-clang-fast -O2 -g target.c -o target_instrumentado
En este ejemplo, usamos la variable de entorno AFL_HARDEN=1 para que el wrapper aplique opciones de fortificación (como -D_FORTIFY_SOURCE=2 y canarios de stack) automáticamente, facilitando la detección de vulnerabilidades de memoria simples. El binario resultante target_instrumentado contiene llamadas a la rutina de AFL++ que actualiza el mapa de cobertura en cada rama ejecutada. Es importante compilar en modo release/optimizado (-O2 o -O3) para obtener mayor velocidad al fuzzear. Tras la compilación, debemos preparar un directorio de casos de prueba iniciales (-i) con uno o más archivos representativos (aunque AFL++ puede empezar con una entrada vacía, siempre es preferible darle alguna pista inicial). Entonces podemos lanzar el fuzzing con, por ejemplo:
$ afl-fuzz -i inputs/ -o resultados/ -M fuzzer01 -- ./target_instrumentado @@
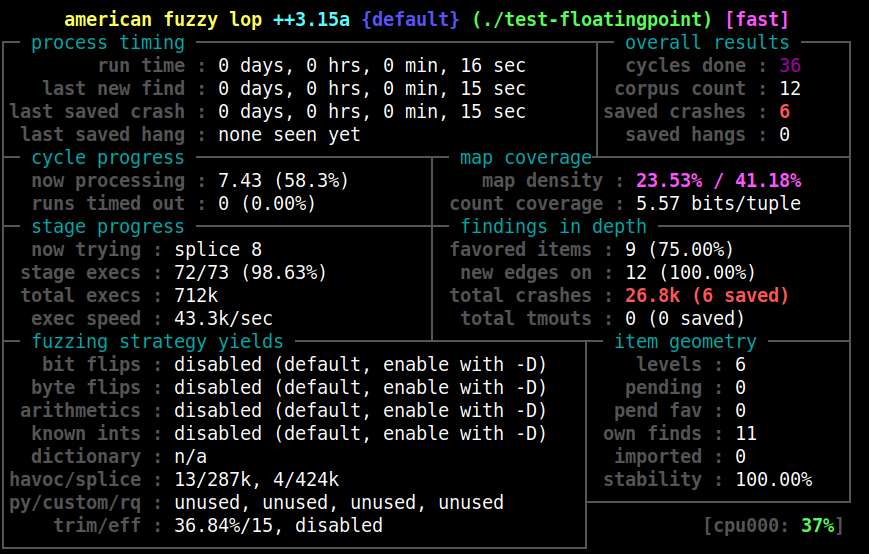
Aquí usamos el modo maestro (-M) nombrando la instancia fuzzer01, con un corpus inicial en inputs/ y la salida de resultados en resultados/. El @@ indica dónde debe el programa objetivo leer el archivo de entrada (AFL++ colocará la ruta del fichero de prueba ahí al ejecutar el binario). AFL++ iniciará la interfaz de estado en consola mostrando métricas de progreso, velocidad (~execs/sec), coberturas, etc. (como se aprecia en la Figura 1) y comenzará a generar mutaciones de los insumos. Es recomendable fijar también un límite de memoria (e.g. -m 200 para 200 MB) y un timeout razonable (e.g. -t 5000 para 5s) dependiendo del programa, para evitar ralentizaciones o falsos hangs.
Fuzzing de binarios sin fuente (QEMU mode): Si no es posible recompilar el objetivo (por ejemplo, aplicaciones de terceros o firmware cerrado), AFL++ ofrece el modo QEMU para instrumentación en binario. Este modo utiliza una versión modificada de QEMU en emulación user-space para ejecutar el programa interceptando cada instrucción de salto, similar a como haría la instrumentación en compilación. Activar este modo es tan sencillo como compilar AFL++ con soporte QEMU (ejecutando ./build_qemu_support.sh en la carpeta qemu_mode una vez) y luego lanzar afl-fuzz con la opción -Q. Por ejemplo:
$ afl-fuzz -Q -i inputs/ -o resultados_qemu/ -- ./objetivo_binario @@
Con -Q, AFL++ iniciará QEMU dinámicamente para cada ejecución del objetivo, obteniendo cobertura sin necesidad de modificar el binario. La contrapartida es que la emulación introduce una ralentización significativa (de ~2-5x más lento que la instrumentación en compilación). Aun así, AFL++ optimizó QEMU (actualmente integra QEMU 5.1) e incluso implementó modo persistente en QEMU, por lo que el rendimiento ha mejorado respecto al AFL original. Este método resulta invaluable para fuzzear software cerrado o incluso malware, y permite combinarlo con otras características (por ejemplo, unicorn mode para fuzzear funciones aisladas en arquitectura simulada, o usar Wine+QEMU para fuzzear ejecutables Windows PE en Linux).
- Harnesses y entradas vía stdin/memoria: AFL++ por defecto espera que el programa lea de un archivo (pasado como argumento
@@). Si el objetivo lee de stdin, simplemente no se coloca@@y AFL redirigirá stdin al archivo de prueba. Para programas que requieren formato específico (ej. un daemon que recibe por red), a veces es necesario escribir un harness o envoltorio: un programa adaptador que toma los datos de archivo/stdin y se los pasa a la función o API interna. Este harness se instrumenta igual que cualquier programa y permite fuzzear componentes que no leen directamente de archivos. Por ejemplo, para fuzzear una función de librería, uno puede escribir un main que lea@@y al contenido le aplique la función objetivo; fuzzear ese wrapper puede ser mucho más eficiente que fuzzear todo el programa que usa la librería.
En este punto, con el binario instrumentado o el modo QEMU activado, y un conjunto inicial de pruebas, ya estamos listos para ejecutar AFL++ y comenzar el fuzzing general. Sin embargo, en ocasiones nos interesará orientar o dirigir el fuzzing hacia ciertas áreas, especialmente si buscamos alcanzar código particular (p. ej., una nueva funcionalidad o un bug conocido). Ahí es donde entra el concepto de fuzzing dirigido.
Fuzzing dirigido con AFL++
El fuzzing dirigido (directed grey-box fuzzing) es una técnica en la que enfocamos la campaña de fuzzing hacia uno o varios objetivos específicos dentro del programa, en lugar de explorar amplia y aleatoriamente todas las rutas. Un caso de uso típico es verificar una porción de código recién parchada (p. ej., fuzzing de regresión) o reproducir un crash conocido guiando al fuzzer hacia ese punto. AFL++ no incorpora de serie un modo dirigido basado en distancias, pero sí puede emplearse en conjunción con herramientas especializadas o configuraciones manuales para lograrlo.
Una de las implementaciones más conocidas es AFLGo, una variante de AFL que calcula pesos en función de la “distancia” de cada camino ejecutado respecto a unas ubicaciones objetivo definidas (por ejemplo, funciones o líneas de código). AFLGo recompila el programa incorporando información de distancia en la instrumentación, de tal manera que el fuzzer favorece las mutaciones que reducen la distancia al objetivo, guiándolo gradualmente hacia las zonas críticas. En pruebas comparativas se ha visto que AFL++ –en su modo estándar de cobertura total– es efectivo encontrando bugs generales, pero AFLGo puede acelerar el descubrimiento de bugs en ubicaciones específicas al enfocarse en ellas.
Si bien AFL++ no trae integrado AFLGo directamente (existen forks e intentos de integrar sus algoritmos en AFL++), un experto puede aplicar fuzzing dirigido con AFL++ de varias formas:
- Estrategia de corpus focalizado: proporcionar semillas de entrada que ya estén cercanas al escenario de interés, de modo que AFL++ parta con ventaja hacia el objetivo. Por ejemplo, si queremos fuzzear funciones de parseo de JPEG en una aplicación grande, iniciar con archivos JPEG válidos ayudará a centrar la exploración en esa funcionalidad.
- Reducir la instrumentación (whitelisting): usando la variable
AFL_LLVM_WHITELISTdurante la compilación conafl-clang-fast, se puede especificar un listado de funciones o archivos fuente a instrumentar. Esto hace que AFL++ solo vea cobertura (y por tanto optimice) en esas áreas, ignorando el resto. Prácticamente dirige al fuzzer a explorar diferencias de ejecución solo en lo marcado relevante. - Ajustes en el schedule y energía: AFL++ permite elegir el esquema de enfriamiento (power schedule) con
-p. Usando-p exploito-p fastpor ejemplo, se puede intentar un enfoque más agresivo para alcanzar rápidamente profundidades de código, lo que puede ayudar a llegar a cierto punto, aunque no garantiza dirección específica. - Herramientas externas de análisis estático + selección de seeds: Otra técnica es usar análisis estático para generar cadenas de llamadas o precondiciones hacia el objetivo, y luego traducir eso en entradas iniciales. No es trivial, pero por ejemplo, herramientas de concolic execution o symbolic execution pueden pre-producir un camino concreto, y AFL++ luego pulirá alrededor de ese camino.
En la práctica, si se requiere fuzzing dirigido estricto, una opción es usar AFLGo para la tarea particular. Sin embargo, AFL++ ha demostrado gran eficacia incluso sin estar dirigido, llegando a descubrir fallos que AFLGo pasó por alto. Un enfoque híbrido podría ser: fuzzear ampliamente con AFL++ para encontrar muchos errores, y en paralelo ejecutar una instancia configurada hacia el objetivo específico (sea mediante whitelist o usando AFLGo como herramienta separada). Ambos enfoques no son excluyentes y, de hecho, compartir los corpus generados entre fuzzers (vía la sincronización de directorios o importando casos de prueba) puede potenciar el resultado.
En resumen, AFL++ por sí solo se orienta a cobertura global, pero el usuario avanzado tiene herramientas para orientar la campaña si lo necesita. A continuación, pasamos a las utilidades complementarias que ofrece AFL++ para maximizar la eficiencia: minimizar corpus, reducir crashers y analizar entradas problemáticas.
Herramientas complementarias: afl-cmin, afl-tmin y afl-analyze
El ecosistema AFL++ incluye utilidades post-proceso muy útiles para trabajar con los casos de prueba generados y con los crashers hallados:
Análisis de casos de prueba – afl-analyze: Esta herramienta realiza un analysis de una entrada dada para inferir qué bytes de la misma influyen en la ejecución del programa. afl-analyze toma un archivo de entrada y lanza el programa múltiples veces, flippeando (mutando) sistemáticamente cada byte y observando cambios en el comportamiento. Al final, produce un informe destacando qué offset de bytes son críticos (por ejemplo, porque al alterarlos cambia la ruta de ejecución o el programa se comporta distinto) y cuáles bytes no afectan en absoluto. La salida suele presentar el input original con marcadores de colores o símbolos que indican importancia. Esto es muy útil para entender la estructura del formato que está procesando el programa: esencialmente realiza una ingeniería inversa aproximada de qué campos del input son relevantes. Por ejemplo, si fuzzeamos un formato de imagen, afl-analyze podría revelar que ciertos bytes (quizás cabeceras mágicas) no pueden cambiar porque son validados, mientras que otros bloques son totalmente libres. Aunque no es infalible, suele dar pistas rápidas sobre formatos complejos. Su uso básico:
$ afl-analyze -i entrada_interesante -o reporte_analyze.txt -- ./target_instrumentado @@
generará el análisis en texto. Cabe destacar que para que afl-analyze sea efectivo, el binario debe estar instrumentado (de lo contrario no puede detectar cambios en el mapa de cobertura). Esta herramienta es una extensión ingeniosa de la técnica de minimización aplicada para propósitos de reversing, y puede ahorrar tiempo al analista al delinear qué partes de un caso de prueba provocan qué ramas en el código.
Minimizador de crash – afl-tmin: Cuando AFL++ encuentra un archivo que provoca un crash (ubicado en crashes/id:...), a menudo ese archivo de entrada puede ser muy grande o complejo debido a las mutaciones acumuladas. afl-tmin ayuda a reducir un caso de prueba crasher al tamaño mínimo que sigue reproduciendo el fallo. Se usa así:
$ afl-tmin -i crash_original -o crash_min -- ./target_instrumentado @@
El minimizador probará eliminar o simplificar bytes del archivo de entrada, verificando tras cada cambio si el programa aún se estrella. Emplea un algoritmo exhaustivo pero optimizado en múltiplas pasadas (borrado de bloques grandes, luego más pequeños, normalización de bytes, etc.), similar al trimming interno que AFL++ hace durante el fuzzing pero más completo. Como resultado, afl-tmin produce un archivo mucho más corto que reproduce el mismo crash. Esto es sumamente útil al reportar el bug, ya que facilita a desarrolladores entender la causa sin ruido adicional. Cabe señalar que afl-tmin funciona tanto con crashes detectados por instrumentación (modo instrumentado) como con simples salidas anómalas (modo no instrumentado). Si el crash requiere ciertas condiciones especiales (por ejemplo, un código de salida específico), se pueden usar variables de entorno como AFL_CRASH_EXITCODE para indicar a afl-tmin qué condición considerar como "crash" válido.
Minimización de corpus – afl-cmin: Durante una campaña prolongada, el corpus de pruebas en el directorio queue/ puede crecer a miles de archivos, muchos de ellos redundantes en cobertura. La herramienta afl-cmin sirve para minimizar este conjunto, encontrando un subconjunto mínimo de archivos que cubra las mismas rutas de código que el corpus original. Su uso típico tras terminar un fuzzing es:
$ afl-cmin -i resultados/queue -o corpus_minimizado -- ./target_instrumentado @@
afl-cmin ejecutará el programa con cada entrada, midiendo cobertura, y descartando inputs supérfluos. Esto reduce drásticamente el corpus (por ejemplo, de miles de casos a quizás unas decenas) sin perder alcance de pruebas, lo cual es valioso para acelerar futuras ejecuciones o para guardar una colección limpia de insumos interesantes. Es aconsejable darle un timeout por caso (-t) mayor que en fuzzing, para asegurarse de no descartar entradas que cubren rutas lentas. Incluso la guía de AFL sugiere usar afl-cmin si partimos de un corpus externo grande antes de iniciar el fuzzing, para arrancar ya optimizados.
En conjunto, afl-cmin, afl-tmin y afl-analyze complementan el fuzzing al permitirnos refinar y entender los resultados. Una buena práctica es, tras obtener algunos crashes, usar tmin para cada uno, obtener entradas mínimas que causan cada fallo único, y luego analyze sobre esos para comprender el desencadenante. Así se acelera el ciclo de análisis de vulnerabilidades halladas.
Demostraciones prácticas: encontrando diferentes vulnerabilidades
Para ilustrar el poder de AFL++ en acción, consideremos cómo detecta varias clases comunes de vulnerabilidades en programas C/C++ típicos. En estos ejemplos prácticos, combinaremos la instrumentación de AFL++ con sanitizadores o herramientas para atrapar los errores en tiempo de ejecución, dado que no todas las vulnerabilidades provocan un crash inmediato por sí solas.
Desbordamiento de buffer en heap
Imaginemos una función vulnerable que copia datos de entrada a un buffer en el heap sin verificar tamaños:
// Código vulnerable (ejemplo hipotético)
void procesar_mensaje(const char *data, size_t len) {
char *buf = malloc(64);
// Copia sin controlar longitud -> posible overflow si len > 64
memcpy(buf, data, len);
...
}
Este tipo de bug (heap overflow) puede no explotar de inmediato si la memoria adyacente no está siendo usada, pero sigue siendo una corrupción de memoria grave. Para detectarlo con fuzzing, podemos compilar el programa con AddressSanitizer (ASan) activado (-fsanitize=address) o utilizar la ya mencionada libdislocator de AFL++. Ambas opciones harán que un overflow fuera de los 64 bytes cause un fallo (ASan abortará el proceso y libdislocator provocará un segfault al escribir en la página protegida). Al ejecutar AFL++ con el binario instrumentado y ASan, cualquier escritura fuera de rango generará un crash (normalmente reportado como SIGABRT debido a ASan). AFL++ entonces registrará el caso de prueba que llevó a esa condición.
Supongamos que la entrada esperada es un mensaje de texto. AFL++ comenzará probando cadenas aleatorias. Inicialmente, es posible que no sobrepase los 64 bytes, pero eventualmente durante la etapa de mutación caótica, podría generar una entrada de mayor tamaño (e.g. 100 bytes de datos aleatorios). Cuando esa entrada se procese, memcpy escribirá más allá del heap asignado y ASan abortará el programa detectando el buffer overflow. AFL++ marcará ese input como un crash reproducible. Analizando el caso reducido con afl-tmin, obtendríamos seguramente un input de 65 bytes que es el mínimo para provocar la sobrescritura (p.ej., 65 caracteres 'A'). Este caso confirmaría la vulnerabilidad.
En fuzzing real, AFL++ ha encontrado montones de heap overflows en codificadores, librerías multimedia, etc., típicamente gracias a combinar su generación de inputs aleatorios con detectores como ASan o libdislocator. Una vez identificado el crash, el desarrollador puede usar la traza de ASan para ver qué línea hizo overflow. AFL++ por su parte habrá continuado buscando otros fallos en paralelo.
Uso de memoria después de liberarla (Use-After-Free)
Los use-after-free (UAF) ocurren cuando un programa libera memoria pero luego continúa usándola, llevando a accesos inválidos. Estos bugs suelen manifestarse de forma menos determinista – a veces no causan fallo inmediato si la zona liberada no se ha reutilizado – por lo que es valioso usar herramientas que hagan la condición determinista. De nuevo, AddressSanitizer es ideal: convierte accesos posteriores a free en aborts inmediatos marcando las regiones liberadas como inaccesibles.
Consideremos un ejemplo simplificado:
char *buf = malloc(32);
free(buf);
// Uso después de free
if (buf[0] == 'X') do_something();
Aquí el acceso buf[0] tras liberar es un UAF. Con ASan, ese acceso produce un crash. AFL++, al explorar rutas de código, podría descubrir esta secuencia si la lógica condicional depende de la entrada. Por ejemplo, supongamos que el programa libera el buffer sólo si el primer byte de la entrada es 'Z', y luego usa el buffer si el segundo byte es 'X'. AFL++ mediante su fuzzing guiado podría encontrar un caso donde la entrada comienza con "ZX", desencadenando el patrón peligroso. ASan detectaría el UAF y se registraría el crash.
AFL++ encuentra UAFs con facilidad si están dentro del alcance de la exploración de ramas. Muchas vulnerabilidades UAF reportadas (p.ej., en navegadores o librerías gráficas) fueron halladas con fuzzers como AFL instrumentados con ASan. Adicionalmente, herramientas específicas como ASan DEDUP se integran bien: por ejemplo, Google OSS-Fuzz utiliza AFL++ con sanitizadores para detectar automáticamente bugs de memoria y agruparlos.
Desbordamiento de entero (Integer Overflow)
Los overflows de enteros ocurren cuando una operación aritmética excede el rango de la variable y produce un valor truncado (p. ej., sumar 1 a UINT32_MAX resulta 0). Por sí solos, los integer overflows no causan excepciones – el programa sigue corriendo con un valor incorrecto. Sin embargo, pueden derivar en problemas serios, por ejemplo, calcular mal un tamaño de buffer (provocando luego un overflow de buffer) o saltarse validaciones de límites. Para cazarlos directamente, podemos usar UndefinedBehaviorSanitizer (UBSan) con la opción de integer overflow (-fsanitize=signed-integer-overflow y/o integer) para que cualquier overflow aritmético genere un abort. Otra estrategia es detectar comportamientos anómalos resultantes, pero eso ya es más manual.
Supongamos esta función vulnerable:
int process(int x) {
int bytes = x * 1000; // potencial overflow si x es grande
char *buf = malloc(bytes);
...
}
Si x es un entero de 32 bits y recibe, digamos, 3 millones, la multiplicación podría desbordarse negativamente dando un valor pequeño y haciendo malloc con un tamaño incorrecto (muy pequeño), seguido quizás de una escritura esperada de 3 GB que desborda ese buffer. AFL++ podría tropezar con este bug a través de un input que controle x. Por ejemplo, si x proviene de datos externos (un campo en un archivo o input), al fuzzearlo eventualmente probará valores grandes como 0x7FFFFFFF gracias a sus heurísticas de valores interesantes. Este valor causaría un overflow. Sin un detector, el programa podría simplemente fallar después cuando intente usar el buffer insuficiente (posible segfault). Pero con UBSan, el overflow en la multiplicación misma disparará un abort inmediato marcado como falla de tipo (runtime error: signed integer overflow). AFL++ registraría eso como un crash (ASan/UBSan terminan el proceso con SIGABRT). Así se detecta la vulnerabilidad en etapa temprana.
Vale aclarar que AFL++ en su modo normal, sin sanitizadores, no detectaría un overflow de entero a menos que provoque un efecto colateral (como un crash subsiguiente). Por ello, las buenas prácticas indican compilar con sanitizadores para encontrar no solo segfaults directos sino también bugs silenciosos que podrían ser explotables. AFL++ soporta bien el overhead de sanitizadores; si el binario instrumentado con ASan es muy lento, se puede compensar corriendo más instancias en paralelo.
Condiciones de comparación (Magic bytes)
Otro tipo de problema que AFL++ aborda bien (gracias a sus mejoras) es cuando la lógica requiere igualar ciertos valores específicos para llegar a cierta rama – los llamados magic bytes o checksums. Un ejemplo:
if (header[0]=='P' && header[1]=='K' && header[2]==0x03 && header[3]==0x04) {
// procesar archivo ZIP
...
}
Aquí el programa solo entra en la rama si los 4 primeros bytes coinciden con "PK\x03\x04" (cabecera ZIP). Un fuzzer naïve tardaría muchísimo en acertar esa combinación exacta por casualidad. AFL++ incorpora la instrumentación CmpLog/Redqueen que enfrenta este reto: cuando detecta comparaciones binarias (como memcmp, strcmp, operadores == contra constantes), intenta inferir los bytes correctos probando retroalimentación. En la práctica, AFL++ al ver que cierta rama casi se toma (por ejemplo, 3 de 4 bytes coinciden) puede activar su modo RedQueen para leer valores del binario comparados y forzar el input a igualarlos. Esto aumenta notablemente la probabilidad de atravesar comparaciones de este tipo. Así, AFL++ lograría generar la secuencia "PK\x03\x04" en el input y cubrir esa rama, habilitando la exploración del código de procesamiento ZIP. Esta técnica ha probado ser muy eficaz para romper formatos con sumas de verificación, cabeceras mágicas, longitudes, etc., sin necesidad de asistencia externa.
En general, AFL++ se ha utilizado para encontrar vulnerabilidades de muchas clases más: double frees, desreferencias de punteros NULL, fallos lógicos, etc. Para cada tipo, la receta es similar: instrumentar, tal vez usar sanitizadores apropiados, y dejar que el fuzzer evolucione las entradas. Los ejemplos anteriores demuestran cómo incluso bugs que requieren condiciones específicas (como valores enormes o secuencias precisas) pueden ser descubiertos gracias al enfoque guiado por cobertura y las mejoras de AFL++.
Comparación técnica: AFL++ vs. Honggfuzz
Tanto AFL++ como Honggfuzz son fuzzers grey-box de código abierto muy populares y efectivos, con filosofías ligeramente distintas. A nivel técnico y práctico, vale la pena compararlos en varios aspectos:
| Aspecto | AFL++ (AFL Plus Plus) | Honggfuzz |
|---|---|---|
| Instrumentación | Instrumentación en compilación (LLVM, GCC) o emulación QEMU/Unicorn. Cobertura software guiada por mapa en memoria. Soporta modos especiales (CmpLog, Ngram) requiriendo recompilación. | Instrumentación por sanitizadores (LLVM SanitizerCoverage) o por hardware (Intel PT, BTS) sin recompilar. También dispone de un modo QEMU propio. Permite aprovechar trazas de CPU para cobertura sin instrumentar el binario. |
| Ejecución y paralelismo | Usa forkserver (multi-proceso) + modo persistente opcional. Se suelen lanzar instancias maestro/esclavo para usar varios núcleos (sincronizando corpus). Límite práctico ~32-64 procesos por máquina antes de sobrecarga. | Multi-hilo en un solo proceso: Honggfuzz internamente maneja varios threads que generan y ejecutan casos en paralelo. Esto simplifica usar todos los núcleos con una sola instancia. Permite tanto varios procesos hijos como hilos según el modo. |
| Velocidad | Muy alta con instrumentación en compilación (decenas de k exec/s). Modo QEMU más lento (x2-x5). Modo persistente aumenta sustancialmente exec/s en funciones focalizadas. En FuzzBench, AFL++ logró excelente tasa de hallazgo de bugs, aunque con sobrecarga mayor que otros en eficiencia. | En modo persistente con harness puede alcanzar tasas enormes (reportes de ~1 millón exec/s en fuzzers triviales). Usa llamadas ptrace eficientes para cobertura en Linux. En comparativas, Honggfuzz a veces halló más bugs únicos que AFL++ más rápidamente, pero su eficiencia por ciclo de CPU puede ser menor en campañas largas. |
| Detección de errores | Depende de señales de crash del sistema y tiempo de ejecución. Integra bien ASan/UBSan (usuario recompila con sanitizers) y herramientas propias (libdislocator) para descubrir memory bugs no evidentes. | Monitorea vía ptrace: intercepta señales incluso si el programa las maneja (asegura que ningún crash pase inadvertido). También soporta fácilmente ejecución con sanitizers y detectar aborts. Ofrece opción de terminar procesos colgados mediante watchdog. |
| Facilidad de uso | Requiere compilar con wrappers o usar env vars para QEMU. Provee interfaz TUI con estadísticas detalladas y múltiples opciones tuning. Gran cantidad de modos y variables config (poderoso pero curva de aprendizaje más alta). | Muy simple de lanzar: un binario honggfuzz que se apunta al target. No necesita paso de compilación extra si se usa modo sanitizer/hw. Comparte corpus entre hilos automáticamente. La salida es generalmente logs y un resumen; menos indicadores en tiempo real que AFL++. |
| Características únicas | Amplia extensibilidad (API de mutadores, diccionarios autogenerados, módulos para formatos). Persistencia en QEMU, fuzzing de kernel (modo snapshot LKM en versiones experimentales), fuzzing distribuido mediante sincronización de colas. | Soporta fuzzing basado en hardware (Intel PT, Intel BTS) aprovechando funcionalidades de CPU para trazar ejecución, lo que es único. Tiene ejemplos listos para muchos softwares (directorio examples/). Incluye modo de fuzzing para Android nativo. |
| Comunidad y mantenimiento | Proyecto comunitario (varios maintainers, merges de muchas contribuciones académicas). Muy activo; versiones frecuentes incorporando lo último en investigación fuzzing. Base en el repositorio AFL original pero con gran refactor. | Iniciado por el investigador de Google Robert Święcki, utilizado en entornos como OSS-Fuzz de Google. Activo y mantenido, aunque con menor número de contribuidores. Foco en ser práctico y eficiente en Linux. |
Resumen práctico: Ambos fuzzers han demostrado ser de los más efectivos. Estudios independientes (e.g., FuzzBench 2021-2022) han encontrado que AFL++ y Honggfuzz suelen liderar en cantidad de bugs descubiertos comparados con otros fuzzers. Honggfuzz a veces encuentra ligeramente más bugs únicos en total, mientras que AFL++ no se queda atrás y suele cubrir un poco más de código gracias a sus instrumentaciones avanzadas. En términos de velocidad pura, Honggfuzz brilla cuando se puede usar su modo persistente con instrumentación ligera, pero AFL++ brilla en versatilidad y en escenarios de caja negra complejos gracias a QEMU y Unicorn.
Para un experto en ciberseguridad, la elección podría depender del caso de uso: si se tiene código fuente y se busca máxima profundidad con técnicas experimentales, AFL++ ofrece más knobs para afinar. Si se quiere rapidez inmediata y aprovechar todos los núcleos sin complicación, Honggfuzz es muy conveniente. Afortunadamente, no son mutuamente excluyentes – de hecho, es factible y a veces recomendable usar ambos en campañas separadas para el mismo objetivo, ya que pueden complementar hallazgos.
Buenas prácticas y optimización en campañas de fuzzing
Finalmente, para aprovechar al máximo AFL++ (o cualquier fuzzer avanzado), se deben considerar ciertas buenas prácticas de configuración y uso:
- Mantener casos de prueba iniciales pequeños y relevantes: La eficiencia del fuzzing disminuye drásticamente con el tamaño innecesario de las entradas. Comience siempre con los insumos mínimos que ejerciten funcionalidad básica. Por ejemplo, en lugar de un archivo de 1 MB, use uno de unos pocos bytes o líneas. Un experimento ilustrativo mostró que al reducir un caso de prueba de 1 kB a 100 bytes, la probabilidad de encontrar cierto bug en las primeras iteraciones pasó de 11% a 71%. Inputs más pequeños significan mutaciones más focalizadas y más rápidas por ejecución. Si solo tiene disponibles corpus grandes, utilice
afl-cminpara recortarlos antes de empezar. - Optimizar el binario objetivo: Compile con optimizaciones de velocidad (
-O2/-O3), deshabilite logs o chequeos superfluos en tiempo de fuzz (por ejemplo, comprobaciones criptográficas que consumen mucho tiempo). Si el programa tiene modos “debug” o “verbose”, apáguelos. Cada ciclo de CPU cuenta: eliminar pausas deliberadas, esperas de red innecesarias (simular respuestas inmediatas si es posible), y usar versiones más simples de las funciones es válido durante el fuzzing. Por ejemplo, si fuzzear un servidor, quizás sea mejor fuzzear la función parser interna aislada en un harness en lugar del servidor entero, para evitar la latencia de sockets. - Usar el modo persistente cuando aplique: Si su objetivo es una biblioteca o función que puede reentrar, vale la pena invertir tiempo en implementar un modo persistente (ya sea con la macro
__AFL_LOOPo adaptando la lógica para procesar múltiples inputs en loop). El aumento de rendimiento es enorme al evitar el costo de fork/exec en cada caso. AFL++ incluso proporciona un template enexamples/persistent_demomostrando cómo hacerlo. Tenga cuidado de reestablecer el estado entre iteraciones para no acumular datos de previas (p.ej., reiniciar estructuras estáticas). - Fuzzear en paralelo y sincronizar: Para aprovechar máquinas multinúcleo, ejecute múltiples instancias de AFL++ en modo sincronizado. Use 1 maestro (
-M) y varias secundarias (-S) compartiendo el mismo directorio de salida. AFL++ intercambiará nuevos hallazgos entre ellos. Esto linealmente mejora la tasa de exploración hasta cierto punto (entre 32 y 64 cores suele escalar bien). Por encima de eso, la sobrecarga de coordinación puede superar beneficios. En entornos distribuidos, se pueden incluso sincronizar corpora manualmente entre máquinas (copiando periódicamente archivos dequeue/). Honggfuzz maneja hilos internamente, pero con AFL++ es responsabilidad del usuario lanzar varias instancias. - Monitorear la estabilidad y cobertura constantemente: La interfaz de AFL++ muestra el porcentaje de estabilidad (bits del mapa que se mantienen constantes) y densidad de mapa. Si la estabilidad es baja, puede indicar que el programa es no determinista (quizá por timestamps, ASLR, hilos de fondo). En tal caso, intente desactivar fuentes de aleatoriedad o fijar seeds de RNG para que las ejecuciones sean reproducibles – fuzzing asume determinismo para evaluar inputs. Una cobertura muy baja puede indicar que el fuzzer se está quedando atrapado en inicializaciones; instrumente solo lo necesario o use diccionarios para ayudar a salir de esas fases.
- Emplear diccionarios y conocimiento del formato: Si el input tiene estructura (ej., JSON, XML, formatos binarios), proporcione a AFL++ un diccionario de tokens clave (
-x palabras.claves). AFL++ también puede autogenerarlos usandolibtokencapo con la opciónAFL_AUTO_DICTal compilar. Un diccionario adecuado puede acelerar mucho la exploración de ramas profundas relacionadas a formatos (p.ej., keys de JSON, etiquetas XML). Igualmente, si sabe de checksums, proporcione funciones o hooks para validarlos o desactivarlos durante fuzz (p.ej., parchear la comparación de checksum para que siempre pase, y así fuzzear el resto). - Tener precaución con timeouts y lentitud: Ajuste el timeout (
-t) para que no sea ni muy alto (perdiendo tiempo en hangs genuinos) ni muy bajo (matando procesos que tardan un poco más en caminos legítimos). Un truco: ejecutar manualmente el corpus inicial con el programa instrumentado y ver tiempos máximos, luego establecer el timeout algo por encima. Use la opción de skip deterministics (-D) si la entrada es muy grande o el formato muy complejo, para saltar la etapa determinista larga y pasar antes a mutaciones random. Monitoree también el cpu load en la UI – AFL++ lo mostrará en verde si no está usando todos los núcleos, en rojo si está saturado. Esto ayuda a decidir si lanzar más instancias o si el sistema está al límite. - Habilitar detección de errores no evidentes: Como se discutió, compilar con ASAN/UBSan (o usar libdislocator) es una excelente práctica para encontrar fallos de memoria ocultos. AFL++ incluso ofrece la variable
AFL_USE_ASAN=1para habilitar ASan fácilmente si el compilador lo soporta, pero hay que tener en cuenta el incremento de consumo de RAM y reducción de velocidad. Otra herramienta útil es CASR (Crash Analyzer for AFL), que se integra con AFL++ para categorizar y resumir crashes automáticamente, facilitando el triage cuando se encuentran decenas de fallos. - No descuidar la post-producción: Cuando finalice la campaña (o periódicamente), use cmin y tmin para depurar el corpus y aislar fallos únicos. Verifique manualmente los crashes en un entorno con depurador o valgrind para confirmar la naturaleza del bug. Asegúrese de reproducir los crashes fuera de AFL++ (ejecutando el programa standalone con la entrada) para eliminar falsos positivos. Documente bien cada hallazgo con su entrada mínima y trace de error; esto ahorra tiempo al comunicarlo.
Siguiendo estas prácticas, se pueden lograr campañas de fuzzing sumamente efectivas. Por ejemplo, reducir un JPEG de prueba de 500KB a uno de 5KB y fuzzear con diccionario de cabeceras JPEG + ASan + 8 procesos en paralelo, puede resultar en descubrir vulnerabilidades en librerías de imagen en cuestión de horas, mientras que una configuración por defecto subóptima podría tardar días o no encontrar nada. La diferencia radica en la expertise en afinar tanto la herramienta (AFL++) como el objetivo.
Conclusiones
AFL++ se ha consolidado como una de las herramientas de fuzzing más robustas y flexibles disponibles para la comunidad de seguridad. Su evolución desde AFL le ha permitido incorporar innovación continua, sirviendo a la vez como banco de pruebas de técnicas de fuzzing de vanguardia y como fuzzer de uso práctico para encontrar vulnerabilidades en software del mundo real. A través de esta detallada revisión, hemos examinado su arquitectura interna – que combina instrumentación guiada por cobertura, forkserver y mutación genética –, sus características destacadas que mejoran el rendimiento y la profundidad (motores de mutación, múltiples modos de instrumentación, soporte de sanitizadores, etc.), y su uso efectivo mediante ejemplos y utilidades complementarias. También comparamos AFL++ con Honggfuzz, otro referente en fuzzing, ilustrando que si bien ambos logran resultados excelentes, AFL++ destaca por su extensibilidad y riqueza de funcionalidades, mientras Honggfuzz lo hace por su sencillez y aprovechamiento directo del hardware subyacente.
En manos de un experto, AFL++ puede adaptarse a numerosos escenarios: desde fuzzing ampliamente exploratorio para descubrir decenas de fallos desconocidos, hasta fuzzing dirigido a condiciones muy específicas. Las mejores prácticas discutidas – desde la preparación de insumos hasta la optimización del entorno – son esenciales para extraer el máximo potencial de la herramienta y obtener resultados en tiempos razonables. Cabe mencionar que el campo del fuzzing sigue avanzando rápidamente (integración con análisis estático, IA generativa para sugerir casos, etc.), pero AFL++ ha demostrado ser un marco lo suficientemente modular y moderno para incorporar nuevos enfoques conforme surjan.
En conclusión, AFL++ representa el estado del arte en fuzzing guiado por cobertura y continúa la senda marcada por AFL, potenciándola para afrontar los retos actuales de la seguridad de software. Todo profesional de ciberseguridad interesado en pruebas automatizadas debería familiarizarse con AFL++, ya que ofrece un laboratorio completo para experimentar con vulnerabilidades y, sobre todo, una herramienta probada para encontrar esos errores críticos que de otra forma permanecerían ocultos.
Referencias
- AFLplusplus – Overview. AFL++ Official Documentation. [Internet]. Disponible en: https://aflplus.plus/
- Fioraldi A. et al. AFL++: Combining Incremental Steps of Fuzzing Research. WOOT ’20, USENIX Security Symposium. 2020. Disponible en: https://www.usenix.org/system/files/woot20-paper-fioraldi.pdf
- AFLplusplus – Features. AFL++ Official Documentation. [Internet]. Disponible en: https://aflplus.plus/features/
- AFLplusplus – Technical Details (afl-fuzz). AFL++ Official Docs. [Internet]. Disponible en: https://aflplus.plus/docs/technical_details/
- AFLplusplus – Fuzzing in Depth (GitHub Docs). AFL++ GitHub repository. [Internet]. Disponible en: https://github.com/AFLplusplus/AFLplusplus/blob/stable/docs/fuzzing_in_depth.md
- Weinholt J. Fuzzing Scheme with AFL++. weinholt.se blog. 2021. Disponible en: https://weinholt.se/articles/fuzzing-scheme-with-aflplusplus/
- AFL 2.53b Documentation – Instrumenting programs for AFL. AFL Official docs (lcamtuf). [Internet]. Disponible en: https://afl-1.readthedocs.io/en/latest/
- Honggfuzz – Project Page. honggfuzz.dev Documentation. [Internet]. Disponible en: https://honggfuzz.dev/
- Comparativa AFL++ vs Honggfuzz (FuzzBench 2022) – Aspromonte et al. Comparing Fuzzers on a Level Playing Field. IEEE ICST 2022 () ()
- AFLplusplus – Performance Tips. AFL++ Official Documentation. [Internet]. Disponible en: https://aflplus.plus/docs/perf_tips/